- Introduction
- The Core Concept Data Stream represents the Core Concept Presentation
- The Continuous Rise Data Stream represents the Continuous Approach to Lectures
- Comparison: the Higher Derivatives of the Core Concept & Continuous Data Streams
- Liminals: Comparing Core Concept with Continuous Approach
- Consolidation of findings
- Evidence
Introduction
What do ‘continuous’ and ‘core concept’ mean in the lecture context? What are the pros and cons of each method? And how does the Living Algorithm fit into this picture?
Cognitive Science's 10-minute rule & Dr. Medina's ‘core concepts’ approach
First a little background. Cognitive experiments have revealed that humans have a hard time paying attention to a lecture or presentation after 10 minutes. The experimental results are so conclusive that they call it the 10-minute rule rather than the 10-minute theory. To break through this 10-minute attention barrier Dr. Medina has successfully employed the technique of organizing his lectures into 10-minute modules, each with its own 'core concept'.
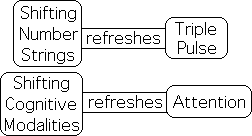
Triple Pulse syncs up with 10-minute rule & Shifting Core Concepts
In our article - The Triple Pulse & the 10-minute Rule, we illustrated that the Triple Pulse simulates cognitive science's 10-minute rule and Dr. Medina's 10-minute core concept strategy. Both the 10-minute rule and the Active Pulse have a 'stubborn timing pattern' that causes them to fade after a set time or duration. Further, just as Dr. Medina shifts to a new core concept every 10 minutes to refresh his audience's attention, the Triple Pulse's data stream must shift from one number string to a different number string at regular intervals to refresh the Living Algorithm's ability to generate a new pulse.
Generalized to Shifting Modalities to capture Attention
We generalized this mathematical mechanism beyond the notion that shifting core concepts is required to retain an audience's attention. Shifting core concepts becomes a subset of shifting modalities at regular intervals to refresh our ability to pay attention. In addition to regularly changing core concepts to refresh attention, there are many institutionalized examples that reflect this pattern. Acts in plays, movements in music, quarters in football, innings in baseball, 3-minute songs on the radio and the coffee break are just a few examples that demonstrate this ubiquitous, everyday phenomenon. The notable feature of each of these instances is that the focus of attention is refreshed by a regular shift in modalities. This refreshment occurs whether the shift in attention is to something totally different or to a new core concept, as in a theatrical or a sporting event. This accords with Triple Pulse mathematics.
Segmentation of an Experience, in some cases, builds to a Climax.
The segmenting of an experience serves to keep our attention. In some cases, this segmentation is also associated with a building momentum. For instance, a play is broken into acts that rise to a climax. A book is written in chapters that collectively build a plot. Dr. Medina broke his lecture into 10-minute core concepts, which lead to a summary conclusion. What does the Triple Pulse model say about the building nature of a lecture, play, or sporting event?
The Core Concept Data Stream represents the Core Concept Presentation
What does Living Algorithm System say about shifting core concepts to build a lecture?
We’ve examined how the ‘shifting modalities’ explanation is adequate to describe the refreshing nature of sleep and the revitalizing nature of a lunch or coffee break. However, it does not address the building nature of a lecture or presentation. For instance, Dr. Medina's 10-minute modules are not isolated segments, but part of a growing whole. Shifting cognitive modalities is slightly different than regularly shifting core concepts to build a coherent lecture. Dr. Medina's personal experience suggests that a presentation based in 10-minute increments of core concepts is more effective than a lecture where information is dispensed without definition. What light does the Living Algorithm Information Digestion System shed on Dr. Medina's claim? To tackle this feature of the learning process, let us dig a little deeper into the Living Algorithm's bag of tricks.
Alternating number strings refreshes the Triple Pulse just as shifting modalities refreshes attention.
In our article on the 10-minute rule, we demonstrated that the Living Algorithm generates the ideal Triple Pulse, when it digests any pair of differing number strings whatsoever – not just 1's and 0s. We further likened these number strings to differing thought modalities – such as activity and rest or work and a lunch break. In other words, shifting number strings refreshes the ideal dimensions of the Triple Pulse, just as shifting mental gears refreshes our Attention. This feature of Living Algorithm mathematics models the refreshing nature of shifting modalities, but does not address the building nature of a lecture or performance.
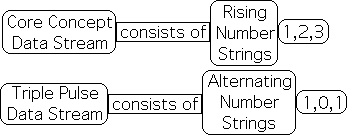
The Core Concept Data Stream
In the attempt to generate a mathematical model for this significant feature of behavioral reality, let us introduce another variation. Instead of a binary data stream consisting of the alternation of 2 differing number strings, let us see what happens when the Living Algorithm digests a data stream consisting of 3 differing number strings. To better model the building nature of a lecture, our number strings become successively larger. Specifically, let us examine the results when the Living Algorithm digests a data stream consisting of a string of 1s, followed by a string of 2s and then a string of 3s. As each of the 3 number strings could represent a different core concept in a lecture, we will call this the Core Concept data stream.
Each number string: 120 data bits long
To attain the maximum dimensions of the ideal Triple Pulse, the number strings couldn't be just any size, but had to be of sufficient length, in this case 120 data bits long. For similar reasons, the number strings in this new data stream must also be 120 data bits long. As, such our Core Concept data stream consists of 120 1s, followed by 120 2s, followed by 120 3s. Just like the ideal Triple Pulse sequence, the Core Concept data stream is 360 data bits long and consists of 3 strings of uninterrupted numbers. There is just one difference. The ideal Triple Pulse data stream is binary - consisting of alternating number strings, for instance 1, 0 and 1. In contrast, the Core Concept data stream consists of the rising number strings 1, 2, and 3.
Is it possible that the Core Concept Data Stream could represent the Core Concept process?
Graph A: Core Concept Data Stream: Living Average & Data
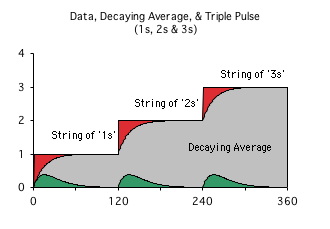
Rising numbers suggest building. As such, the Core Concept's Data certainly reflects the growing nature of the lecture. What about the Living Algorithm's digestion process?
Graph A at right is a visualization of what happens when the Living Algorithm digests the Core Concept data stream – a string of 1s, 2s, and 3s. The Data (red) is in the background. Note that three red blocks (the three data strings) continue behind the grey. In line with the building nature of a lecture, the red area steps ever higher. (Please note there is a link below each graph that describes the unique nature of the Living Algorithm’s Graph Design.)
The Core Concept's Living Average models the core concept process.
The Living Algorithm's digestion process produces the rates of change (the derivatives) of any data stream. The data stream's 1st derivative, the Living Average, is the grey area highlighted in the foreground. The green pulses are visualizations of the data stream's 2nd derivative. Note how the Living Average reflects the growing nature of the information, except that the corners are rounded. The string of 1s raises the Living Average from 0 to 1. Then the string of 2s raises the Living Average from 1 to 2. Finally, the string of 3s raises this grey swatch, the 1st derivative, from 2 to 3.
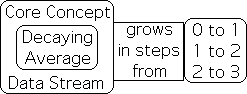
In similar fashion, each core concept builds upon the prior core concept to create a deeper level of complexity. It seems that the Core Concept's Living Average is congruent with the Core Concept lecture process.
This congruence lends support for the notion that the Core Concept Data Stream could represent the Core Concept process.
![]()
The Continuous Rise Data Stream represents the Continuous Approach to Lectures
Summary of relationship between the Core Concept Model and Core Concept Approach
Let's summarize for retention. To take advantage of the 10-minute rule, Dr. Medina suggests breaking an hour lecture into 10-minute modules. Each module has a core concept and the combined modules build on a common theme. This system has proven to be a successful teaching technique. The Living Average (the 1st derivative) of the Core Concept Data Stream mirrors this phenomenon. Each number string corresponds with a core concept. The string of 1s corresponds with the first core concept, the string of 2s with the 2nd, and so forth. Further, the Living Average corresponds with the increasing complexity of the lecture (Graph A). (We chose a string of 3 pulses for our study, but that could just as well be 4 or 5 pulses.) It is evident that our Core Concept Model exhibits patterns of correspondence with a lecture of increasing complexity built around 10-minute modules, each with its own core concept.
What is the difference in the two approaches?
Why is utilizing the 10-minute core concept approach to lecturing more successful than a continuous approach? The common sense method of presenting a continuous sequence of facts for the entire class duration does not take into account the well-established 10-minute attention span. Why does this matter? Let’s see what the Living Algorithm’s bag of mathematical tricks reveals about these contrasting teaching techniques.
Continuous Rise Data Stream
To test the teaching scenario that utilizes what we shall call the Continuous Approach, let's employ a data stream that is an arithmetic series of numbers that steadily increases by specific increments. We feel that this series models a stream of presented facts that build on each other. In this case, we will use the following numbers – .012, .024, .036, …, 3.988, 4.000. The numbers gradually rise from 0 to 4. We will refer to this as the Continuous Rise data stream.
Each data stream: 360 data bits long & same quantity of information
While the Continuous Rise data stream consists of a sequence of numbers that are continually growing, our Core Concept data stream consists of 3 number strings (120 1s, 120 2s, and 120 3s). We have taken precautions to make this a fair comparison. Both data streams consist of 360 data bytes and both data streams add up to an equal amount. In other words, each data stream contains the same quantity of information.
Let's see what happens when the Living Algorithm digests the Continuous Rise data stream.
Graph B: Living Average of Continuous Data Stream
B. Continuous Rise: Living Average & Data
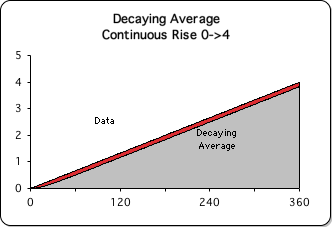
Et Voila! The Living Average (the 1st derivative) of the Continuous data stream is the grey area in the foreground. The Data is indicated by the red area in the background. The Living Average is overlaid upon the Data. As promised, the values (red) of the Continuous Rise data stream rise in small increments from 0 to 4. The Living Average (grey) rises alongside to just a little less than four. The difference between these two quantities is the data residue (the thin red area), which rises just above the Living Average. The remainder of the Data area is equal to and obscured by the Living Average area.
Continuous Rise Living Average models Continuous Approach Lecture.
Graph B is a visual representation of a common sense model for how we learn. It is based upon the assumption that humans are learning machines that can continuously absorb information. It is evident that the Living Average of the Continuous Rise data stream is congruent with the Continuous Approach to lecturing.
This congruence lends support for the notion that the Continuous Rise Data Stream could represent the Continuous Approach lecture process.

Comparison: the Higher Derivatives of the Core Concept & Continuous Data Streams
Now that we've established that our 2 data streams could represent the differing lecture processes, let us see what the Living Algorithm System reveals about each approach? We’ve examined the Living Average (the data stream’s 1st derivative – rate of change) of each data stream. Now let's see what happens when the Living Algorithm digests the exact same data streams to produce the higher derivatives.
Graph C: the Higher Derivatives of the Core Concept Data Stream
C. The Higher Derivatives:
Core Concept Data Stream
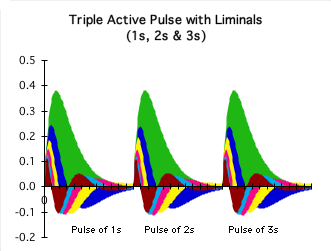
At right is a visual representation of the higher derivatives of the same Core Concept Data Stream that generated Graph A. The green area in the background represents the 2nd derivative of the data stream. The multicolored areas in the foreground are the higher derivatives of the same data stream - deemed the Liminals as a group.
The ideal Triple Pulse (shown below) consists of an alternation of Active and Rest Pulses. In contrast, the Core Concept data stream only generates Active Pulses, but no Rest Pulses. As such we refer to the green area as the Triple Active Pulse.
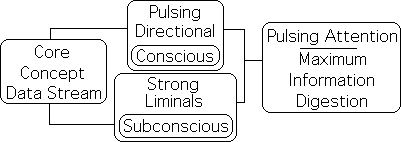
Our studies regarding sleep deprivation and naps suggested that the Active Pulse is associated with conscious attention. As such, the Triple Active Pulse could correspond with three 10-minute pulses of attention. This correspondence provides further validation for our employment of the Core Concept data stream as a model for the Core Concept approach to lecturing.
Graph D: the Higher Derivatives of the Continuous Rise Data Stream
D. Continuous Rise: Directional & Liminals
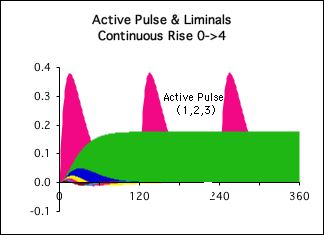
Now let's what happens when the Living Algorithm digests the Continuous Rise data stream. Surprise, surprise! Never seen this before. The Directional, the data stream’s 2nd derivative (green) gradually rises to a little less than 0.2 and then reaches a plateau, presumably forever, as long as the data keeps rising in value. The Liminals, the higher derivatives, are represented by the multicolored curves. They rise just a little bit and then fade forever.
Continuous Conscious Attention of Continuous Approach
As mentioned, our sleep studies linked the Directional (the green area) with conscious attention. The graph reflects the human machine model perfectly. The machine takes a little time to warm up, but keeps running as long as new ‘fuel’ continues to be supplied. This is congruent with an underlying assumption of the Continuous Approach: we are absorbing information as long as we are conscious. The behavior of the mathematical model (the green area) certainly seems to support this interpretation. This correspondence provides further validation for our employment of the Continuous Rise data stream as a model for the Continuous Approach to lecturing.
Sleep-related studies associate Directional, the 2nd derivative, with Conscious Attention.
For contrast, in the background we have also included the Triple Active Pulse (magenta). Just as the green area is the 2nd derivative (the Directional) of the Continuous Rise Data Stream, the magenta sector is the 2nd derivative of the data stream that we employed to represent the Core Concept Approach. As mentioned, our sleep studies associated the 2nd derivative (the Directional) with conscious attention.
![]()
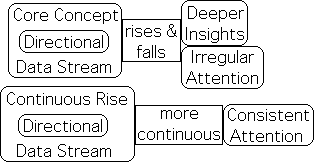
Conscious Attention – Core Concept: Pulse-like vs. Continuous Approach: Continuous
If these associations have any validity, conscious attention has a distinct pulse-like nature in the Core Concept Approach. In contrast, conscious attention is continuous in the Continuous Approach.
Our common sense supports the 2nd interpretation. Most of us believe that as long as we are conscious, we are also attentive. Of course, the scientifically verified and established 10-minute rule invalidates this common sense notion and supports the pulse-like nature of attention. What does the Living Algorithm System suggest about these strange inconsistencies between common sense and scientific 'fact'.
Wouldn't Continuous Conscious Attention be more effective than Pulsing Attention?
Let us continue our comparison of what the 2 mathematical models suggest about their respective approaches to teaching. Notice how high the Core Concept's magenta pulses soar above the Continuous Approach’s green sector. Personal experience suggests that these peaks are associated with insight and inspiration. But who needs inspiration to hear a lecture? As long as one is awake, one can ingest information. At least that is our common sense thinking and what Graph D suggests. Further, the green sector is more consistent, as compared with the severe ups and downs of the Triple Active Pulse (magenta). One might reason that what the green sector loses in insight is more than made up for in consistency of attention.
Liminals: Comparing Core Concept with Continuous Approach
Graphs E & F: A Comparison of the Liminals
Now let's compare the behavior of the Liminals (the higher derivatives) of the two data streams. They are represented by the multicolored swatches in the two graphs that follow.
Graph E: Continuous Approach Liminals scrawny
E. Continuous Approach
Notice how scrawny the Liminals are when the values of the data stream rise continuously (Graph E). The multicolored swatch in this graph rises to about 0.05 and then fades out completely. Their entire cycle ends before the first pulse of 120 data bytes comes to a close.
Graph F: Core Concept Liminals vibrant
F. Core Concept Approach
Contrast that with the Liminals from the Core Concept data stream (Graph F). Notice how vibrant they are in comparison. Each of the three pulses rise to well over 0.2 (5X higher than the aforementioned Liminals). Obviously, the Liminals of the Core Concept Data Stream are far more exuberant than their cousins in the Continuous Rise Data Stream.
Continuous Approach inhibits the Subconscious Digestion of Information
Prior studies have suggested that the Liminals are loosely associated with our subconscious ability to digest information (unconscious cognition in the lexicon of cognitive science).
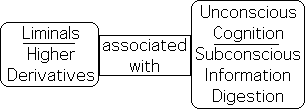
If this supposition is true, the graphs tell a very different story. In Graph E, the Liminals (the anemic looking multi-colored swatch) are severely curtailed when the Continuous Approach data stream is employed. In terms of our correspondences, when information is presented in a continuous fashion without definition, our subconscious ability to digest information suffers. Note this is true even though we remain conscious.
Core Concept Approach augments the Subconscious Digestion of Information
In contrast, the Liminals in Graph F are vibrant and expansive. These Liminals are a product of the Core Concept data stream. Relative to our correspondences, subconscious operations (unconscious cognition) are optimized when a lecture is presented in core concept modules. Remember the subconscious is vital for digesting information. If these subconscious are diminished, this would restrict our ability to learn. Accordingly, this mathematical process both simulates and supports Dr. Medina's 10-minute core concept strategy. In short. the scrawny Liminals of the Continuous Rise data stream indicate that our ability to digest information is inhibited, while the vibrant Liminals of the Core Concept indicate that this same ability is augmented.
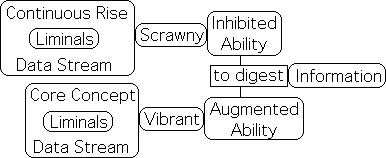
Consolidation of findings
Let's consolidate our findings. We chose a data stream that rises incrementally to model the Continuous Approach to learning. Further, we chose a data stream that rises in steps to model the Core Concept Approach. The Living Algorithm digests both data streams. The above graphs are visualizations of the mathematical results. What do they suggest?
Continuous Presentation of Facts effective if we learn like a computer
We examined and compared the behavior of each member of the Living Algorithm Family of derivatives. A preliminary examination of the Living Average (1st derivative) from the Continuous Approach suggests that this approach to learning would be effective if a human could absorb data in the same manner as a computer - continuously without limitation. An examination of the Directional (2nd derivative) from the Continuous Approach confirms these findings. Unlike the other data streams we've examined, the Directional, after the initial surge, remains constant – never fading or increasing. Prior studies have associated the Active Pulse, a special Directional, with consciousness. This correspondence suggests that information presented in a continuous fashion at least keeps the listener awake.
Liminals in Continuous Approach: Lights On. Nobody Home
The turn-around occurred when we examined the Liminals (the higher derivatives). The Core Concept Liminals are vibrant and dynamic, while the Continuous Rise Liminals are scrawny and fade rapidly. The Continuous Rise Directional (the 2nd derivative) is going strong, while the Liminals are severely diminished. Let us suppose, as our studies have suggested, that the Liminals are associated with the subconscious digestion of information and the Directional with consciousness. If this is true, even though the Listener appears attentive, it is very possible that the presented information will not be digested or retained. Although the light of consciousness is ‘on’ (the Directional), there is no mechanism to digest the information (the Liminals). It is as if the Listener is open for business, but nobody is home. Most of us have had this experience in a presentation or lecture when new information is presented without a break. We are wide-awake and nod at appropriate moments, but are unable to comprehend or retain what is being said.
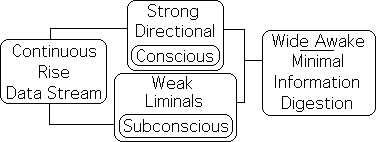
Core Concept Approach: All Data Stream Derivatives operating at full capacity
Conversely, in the Core Concept Approach, all the data stream derivatives (the Active Pulse, i.e. the Directional, and the Liminals) are operating at full capacity. If the same associations hold, then attention (the Active Pulse) and subconscious digestion of information (the Liminals) augment each other to maximize learning potentials. Our theory is supported by Dr. Medina’s core concept teaching method based upon the 10-minute rule.
Evidence
Core Concept Approach engages complete range of mental faculties
If the above correspondences are correct, the mathematics of the Living Algorithm System suggests that the Core Concept Approach to teaching is likely to be more successful than the Continuous Approach. The Core Concept Approach is potentially more effective because our mental capabilities are more completely engaged – specifically our subconscious ability to digest and assimilate information.
Medina's Core Concept Lecture method as supporting evidence
Is there any evidence in support of this proposition?
Teaching has been used as an example of the effectiveness of this strategy. Cognitive science’s 10-minute rule constitutes a measurable relationship between the instruction method and comprehension. Dr. Medina based a highly successful teaching method on the 10-minute rule.
Core Concept Strategy embedded in our culture.
Teaching is but one example of how the Core Concept Approach has been used successfully. Our culture has institutionalized this strategy in numerous ways: a sequence of pieces in a musical performance, a series of innings or quarters in sports, chapters in books or even acts in plays. Why don’t we have books without chapters, plays without acts, or football without quarters? We can even loosely extend this compartmentalization of ideas to punctuation, which organizes a series of words into thoughts. Why aren’t there written works without commas, periods and quotation marks? Could it be that our punctuation marks break our sentences, paragraphs, essays, and books into mini-core concepts?
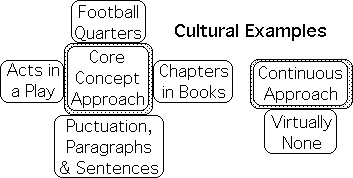
Continuous Strategy rare in our daily lives
Why is there a conspicuous absence of the Continuous Approach in our daily lives? Could it be that this strategy fails to keep our attention? Why does our culture regularly employ the Core Concept Approach? Could it be that this strategy inherently holds our attention more successfully?
Pulses of Concentrated Information easier to digest than Continuous Information Flow
Why? Our theory is that an underlying mathematical rhythm or pulse governs our attention span, whether we like it or not. We have seen this phenomenon in the well-established 10-minute rule. Further, Living Algorithm Mathematics determines the rules behind this underlying pulse. One of the rules seems to be that pulses of concentrated information, such as core concepts, engages the complete range of our mental faculties, while a continuous information flow puts our subconscious information digestion process to sleep.
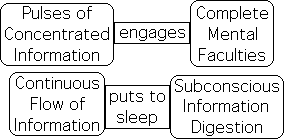
Core Concept syncs w/pulsing Attention span: Continuous Approach w/mind fuzz
The Core Concept Approach syncs up with the pulsing of attention as we experience the acts of a play, the quarters of a football game, or even the chapters of a book. Further, the Continuous Approach syncs up with our experience of mind fuzz during an undifferentiated lecture, performance or musical concert. Our brains seem to need some type of punctuation to assimilate information. Once again, the Living Algorithm's digestion process mirrors our experience of reality. It seems that humans are less able to digest information when it is presented as a steady stream. Instead, we must digest information in smaller chunks to make it easier to assimilate.
What purpose does the Rest Pulse have, if an Active Pulse is refreshing?
This analysis, while answering certain questions, has raised other questions. For instance, if an Active Pulse refreshes an Active Pulse, why can't human beings engage in one Active Pulse after another? What is the purpose of a Rest Pulse, if the Active Pulse serves the same refreshing purpose? We certainly don't know. For some suggestions in this regard, check out the next article in the stream – The Triple Active Pulse.
To better assimilate the current article, we highly suggest reading about Life’s response to this article – From Core Concept Congruence to Symbol Refinement.