- Probability’s Data Sets vs. Living Algorithm’s Data Streams
- Field of Action determines Nature of Questions and Answers
- Probability Permanent Features; Living Algorithm Changing Relationships
- Data Set of 1s vs. Data Stream of 1s
Probability’s Data Sets vs. Living Algorithm’s Data Streams
Similarities suggest that Living Algorithm is Probability’s Child
There might be some who feel that the Living Algorithm is but a subset of Probability. On first glance, the two approaches to data analysis seem exceedingly similar. Both Probability and the Living Algorithm employ averages and deviations to characterize data. Due to these similarities, it would seem that both would follow similar technical guidelines and have a similar purpose. As such, one might consider Living Algorithm mathematics to be just a branch of Probability. But, as we shall see, instead of being Probability’s subject, the Living Algorithm rules her own realm. While the two have similar tools, they have mutually exclusive, yet complementary, domains. Each has a unique purpose and field of action.
Probability’s Static Data Sets: Living Algorithm’s Dynamic Data Streams
Each system analyzes data. Probability, however, processes Data Sets, while the Living Algorithm digests Data Streams. Data Sets are fixed in size, and Data Streams are continually growing. More importantly, Probability is limited to providing information about the general features of the entire data set, while the Living Algorithm can only provide information about individual moments in a data stream. In short the mathematical perspectives have unique fields of action. In fact, each is incapable of perceiving data from the other’s perspective. These differences are crucial to how each form of mathematics manifests their abilities.
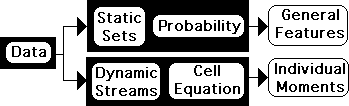
Directional & Liminals are unique to Dynamic Data Streams
Although there are some striking similarities between the two, each has measures that are unique to its system. For instance, the Living Algorithm includes the Directional as a member of her Family of Measures. The Directional determines the tendencies of the data stream and gives birth to the Liminals. Further, the ideal Triple Pulse depicts the Directional of a specific and significant data stream. Accordingly, the Directional is central to Information Dynamics. This measure is unique to data streams. Probability has neither a Directional nor Liminals in his bag of tricks. Because Probability’s data sets are static, they have no direction.
Living Algorithm & Probability belong to orthogonal Universes
Similarly, Probability includes many measures and forms of analysis, which are perfect for analyzing the features of static data sets, but are inaccessible to Living Algorithm mathematics. In general, Probability’s measures reveal the general state of the Universe, while the Living Algorithm Measures reveal the individual nature of its Flux. Consequently their fields of action and the questions they inspire are entirely different. The Living Algorithm & Probability belong to orthogonal universes, which intersect in Human Behavior.
Field of Action determines Nature of Questions and Answers
Field of Action: Probability – Static Data Sets, Living Algorithm – Moments in Dynamic Data Streams
The field of action (focus of attention) is incredibly important, as it determines the nature of the questions asked and therefore the answers obtained. Probability’s field of action is comprised of static data sets whose members have identical features. The question that arises is: What is the nature of these data sets and what is the relationship between them? Probability answers these questions by making definitive statements about these attributes. In contrast, the Living Algorithm’s field of action (focus) is growing data streams. The posed question: what is the nature of the most recent moment in the data stream in relationship to what went before. Accordingly the Living Algorithm specializes in making suggestive statements about individual moments in the stream.
Impossible to merge perspectives
It is impossible to merge the perspectives. Inherent mathematical constraints prevent Probability from defining individual moments and prevent the Living Algorithm from defining general features. They are mutually exclusive perspectives. Let’s examine one of the significant differences between these two approaches to data analysis due to their differing fields of action.
Probability’s Specialty: determining permanent features of Fixed Data Sets
Because Probability concerns himself with static data sets, his predictive power is well defined. For the population under consideration, Probability determines the values of central measures (his averages) that are fixed, absolute, and never changing. This is because Probability’s field of action consists of fixed, non-dynamic data sets (populations). Invariable, exact, permanent results are the order of the day. Probability’s specialty is revealing the fixed features of any data set.
Living Algorithm Specialty: determining evolving features of Dynamic Data Streams
Because the Living Algorithm concerns herself with dynamic data streams, her predictive power is suggestive, not definitive in anyway. That would be impractical, as her predictive power is relative to a dynamic context that is ever changing. Dynamic, constantly changing input leads to changing results. Impermanence is the order of the day. (Physicists everywhere are cringing.) The Living Algorithm’s specialty is revealing the trends of the data stream under consideration – the trajectories of the most recent moment. She accomplishes this task by analyzing the way an information flow changes over time (the changing momentum of the data stream – the dynamics).
Probability – the fixed State of the Universe; Living Algorithm – the Universal Flux
Probability’s field of action is the fixed State of the Universe, as it pertains to the permanent nature of fixed data sets. This form of analysis applies particularly well to material systems, whose physical laws are constant and never changing. The Living Algorithm's field of action is the Universal Flux – the evolving state of data streams. This form of analysis applies particularly well to living systems, whose biological processes are constantly evolving.
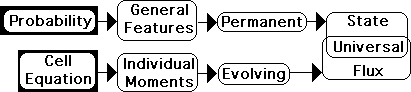
Probability Permanent Features; Living Algorithm Changing Relationships
Probability’s snapshot of a data set applies forever
To illustrate these concepts let’s look at a few examples. Probability can take a computational snapshot of a data set and apply the insights that are derived backward and forward in time to every data set that shares the same characteristics. This is why his conclusions are so powerful regarding matter. These insights apply to every piece of matter that has ever existed because matter sets are uniform. For instance, water molecules have always been and will always be the same.
Probability has Difficulties with Data Sets of Constantly Changing Human Behavior
A fundamental reason that Probability has such a difficult time describing human behavior has to do with evolution, both social and biological. Due this evolutionary nature, the data sets regarding human behavior are frequently not uniform with respect to time. People are continually changing from birth to death and human culture is continually evolving. Consequently, the insights derived from one data set are harder to apply to other data sets of humans. For instance, care must be taken when comparing young people with old people – Africans with Europeans – modern women with Stone Age women – or college students with the rest of humanity. Many reputable studies of human behavior, which have been acceptable in all other regards, have been fatally flawed due to inappropriately applying the results from one data set to another data set of seemingly similar nature. In contrast, since it is universally assumed that electrons in all times and places have always been identical, it is appropriate to apply the results from one data set of electrons to another.
Living Algorithm’s snapshot of a data stream reveals relationship between moments
The Living Algorithm can take a computational snapshot of a moment in the dynamic changing scene of the data stream and also come up with some definite answers (the Living Algorithm’s Predictive Cloud). But these definitive answers are immediately eroded by the incoming data - the constantly changing external landscape. Accordingly, a snapshot of a data stream only applies to that moment. The snapshot reveals the ongoing relationship between data points, not the permanent nature of the set.
Data Set of 1s vs. Data Stream of 1s
Creative Pulse Data (120 1s): Boring for Probability, Exciting to Living Algorithm.
To illustrate these concepts let's look at some specific examples to see what they reveal about the dual perspectives. Let’s see what happens when we employ the two approaches to analyze a data stream or set consisting of 120 consecutive 1s (the Creative Pulse data stream). Probability finds this data set incredibly boring. It is so simple that the Average and Standard Deviation can be determined instantly without any calculations. The Average of this data set is 1 and the Standard Deviation is 0, as there is no change. In contrast, the Living Algorithm finds this data stream so interesting that there is an entire computer experiment accompanied by a written notebook devoted to it. Further, the mathematical results are related to experimental findings regarding behavior.
Data Set of Men’s heights: Probability’s Specialty, Living Algorithm’s Impossibility
For contrast, let’s employ the two approaches to analyze the data set containing the height of every man between 20 to 30 years old in the United States circa 2011. Probability can tell you the average height, the expected height range, and even how many heights it takes to create a smaller representative sample that reflects the entire population. In contrast the Living Algorithm is helpless before this data set. Her field of action is ordered data streams. The current example is an unordered data set. What could she possibly say about an unordered data set, when her specialty is ordered data streams?
Probability: Permanent Features; Living Algorithm: Changing Relationships
The central measures (averages) that Probability employs to characterize each data set are permanent – never changing. In contrast the Living Algorithm never characterizes entire data streams, only individual moments in the stream. Further the measures (the predictive cloud) that the Living Algorithm employs to characterize each moment in the data stream are unique to that moment. They cannot be applied to the data stream in its entirety. In relation to one another, they are in a constant state of flux - adjusting appropriately to each new data point. Probability’s averages apply to the entire set, while the Living Algorithm’s predictive cloud only applies to individual moments.
Living Algorithm: Each Moment plays a unique role – Probability: Not
Furthermore, these clouds, as the name implies, evolve with each new data point. For instance, although the Creative Pulse data stream only consists ones, each moment has a unique role to play with its own evolving predictive cloud. This provides the individual fingerprint for each moment in the stream. For Probability each 1 is just another 1 in the group – no individuality whatsoever.
Probability: No moments – can’t analyze relationship between data points
Just as data sets don’t exist for the Living Algorithm, data stream moments don’t exist for Probability. This has to do with the way each processes information. The Living Algorithm relates individual instants (data points) in the data stream to create moments. Probability does not recognize a relationship between individual points, except in relation to the general data set. Even when Probability analyzes the relationship between two data sets, his proclamations are absolute and apply to the data sets as a whole, not to individual moments. The sets are related or not by a specific percentage. Probability says nothing about individual moments, as his field of action is data sets, not data stream moments. The field of action determines the nature of the explanation. What can Probability possibly say about individual data points when his field of action is data sets?
Living Algorithm: Individual data points affect future moments
In contrast, the Living Algorithm’s field of action consists of data points in a stream. To indicate how important each data point is to the Living Algorithm, let’s examine what happens when a 0 replaces any of the 1s in the Creative Pulse sequence. This slight change totally transforms the internal landscape of the remaining predictive cloud. Because these transformations were so dramatic, a series of computer experiments were run exploring these variations. (See Creative Pulse Review.) Even though the Living Algorithm’s predictive cloud doesn’t give any indication as to the state of the entire data stream, the predictive cloud says a lot about the relationship between individual moments.
Probability: Individual subservient to the Group
In contrast, substituting 0s for 1s in Probability’s data set changes its permanent nature, but has absolutely no influence upon the future of individual moments. Because moments don’t exist in Probability’s system there are no ‘future’ moments to be affected. Probability does not care about the individual, except in relation to the whole. For Probability, the individual is subservient to the group.

Difference due to method of processing Data
This difference between the two systems is due to the way they process data. For example, each approach determines their respective measure for range of variation in a similar, yet distinctly different, fashion. Both employ the same formula, but with one crucial difference. To compute the Standard Deviation, Probability relates the individual points to the general mean average of the set. On the other hand, to compute the Deviation, the Living Algorithm relates individual data points to the Living Average of the preceding moment.
Summary
This discussion has clarified a few issues. Although the Living Algorithm and Probability have similar measures (averages and deviations), each has a unique field of action. Probability’s field of action is static data sets. He computes universal features of these sets with no attention to the individual points, except as to how they contribute to the whole. The Living Algorithm’s field of action is individual moments in a dynamic data stream. She computes specific features of each moment with no regard for the set as a whole. Accordingly, their fields of action are complementary, each with a unique perspective. Neither is a subset of the other. Probability specializes in determining the general features of fixed data sets, while the Living Algorithm specializes in determining the changing features of individual moments in a data stream. As well as her other monikers, the Living Algorithm System could also be deemed the Mathematics of the Moment.
Links
It is evident that the Living Algorithm and Probability are complementary systems. However, the use of probabilistic measures is widespread in the scientific community, while the Living Algorithm is not employed at all. Does this indicate that the Living Algorithm System has no scientific validity? The Living Algorithm certainly provides interesting information about the moment. But does this information have any scientific utility? To explore the issues behind this question, read the next article in the stream – General Patterns vs. Individual Measures.
Despite this successful interaction, Life is thrown into doubt. To understand why check out Probability challenges Living Algorithm's scientific credentials.