Section Headings
Traditional Mathematical Functions vs. the Living Algorithm
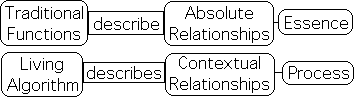
Obedient Functions describe Essence: Disobedient Functions describe Process
Living Algorithm's Data Streams vs. Probability's Data Sets
Electronic Information Processing vs. Living Algorithm's Information Digestion
Absolute Essence vs. Contextual Process
Synopsis
Why aren't traditional mathematical systems able to encompass Attention? Are there some inherent limitations that prevent them from being the Mathematics of Living Systems? The article examines the fatal flaws of Physics, Probability, and Computers and illustrates why Data Stream Dynamics is ideally suited for this role.
Data Stream Dynamics, the mathematical system generated by the Living Algorithm, is startlingly different from traditional mathematical approaches. This is to be expected as the processes of this deceptively simple algorithm provide the foundation for our Theory of Attention, a mathematical theory that links the synergy of attention and directed mental energy with the dynamics of information flow.
The article Mathematical Overview delineates some of the special features of the Living Algorithm. What are the differences between these features and traditional mathematical approaches? This article attempts to differentiate the Living Algorithm from 3 mathematical systems: the traditional functions of science, probability and traditional information theory.
Traditional Mathematical Functions vs. the Living Algorithm
Let us begin by contrasting the Living Algorithm with the traditional mathematical functions that Physicists and Chemists employ to characterize the physical universe. Epitomized by the equations of calculus, this type of mathematical function has 2 or more variables. The simplest form is written below.
Y, a variable, is a function of X, another variable. This type of equation expresses an absolute relationship between variables. The relationship between these variables can be plotted as a graph on Cartesian coordinates – the x-y axis. The ordered pair would look like this: (X, Y).
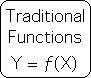
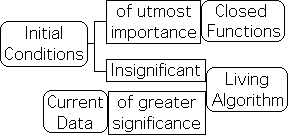
For these functions, the starting point, i.e. the initial condition, is of utmost importance, as it determines every subsequent value. Due to matter's deterministic nature, this type of equation is ideal for dealing with material systems. Employing traditional functions such as these to characterize the behavior of matter has met with spectacular success.
![]()
In contrast to these traditional functions, the Living Algorithm is a recursive function. Recursive functions are based upon the repetition of a process that refers back to itself. In other words, the current result is a function of the preceding result. The simplest form is shown below. Note that 'X' is the only variable. However, it is an ordered variable, as indicated by the subscript. Because there is only 1 variable, plotting these functions on the x-y coordinates requires the X on one coordinate and the N on the other. The ordered pair could look like this: (N, XN).
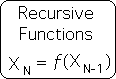
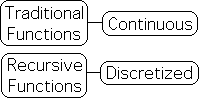
It is possible to include a subscript for traditional functions, but it would be redundant, i.e. unnecessary information, as the subscript for each variable would always be identical. However there is a significant difference between the 'N' employed in traditional and recursive functions. For traditional functions, the 'N' can represent any number on the real number line. As such, traditional functions represent an absolute and continuous relationship between variables.
In contrast, the 'N' in recursive functions must be a positive integer, as it represents the repetition of a process. For instance, when N equals 5, it indicates that the process has been repeated 5 times. There are no such things as partial processes. It either occurs or it doesn't. Because of these limitations on N, a recursive functions represents a discretized, rather than continuous, process. This feature is highly significant when it comes to living systems.
Obedient Functions describe Essence: Disobedient Functions describe Process
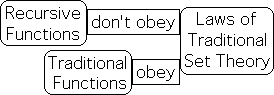
Traditional functions are also referred to as well-founded functions. A well-founded function obeys the axiom of regularity. This means that they don't contain themselves. Because they are not self-contained, they obey the laws of traditional set theory. As they are well behaved, we sometimes refer to these traditional equations as 'obedient' equations.
In contrast to obedient functions, recursive functions are self-contained, i.e. self-referential/reflexive. Because they are self-contained, they do not obey the axiom of regularity. As such, recursive functions don't obey the laws of traditional set theory. Because they violate the law against self-containment, we sometimes refer to them as 'disobedient' equations.
Traditional functions are not based upon a repetitive process and are not reflexive. These obedient functions express an absolute relationship between variables. Newton's F= m*a and Einstein's E = mc2 are famous examples of this type of equation. The first describes an absolute relationship between force, mass and acceleration; the second between energy, mass and the speed of light. Due to the permanent nature of these relationships, they describe absolute essences. Each entity is either inside or outside the box. In such a way, they adhere to the laws of traditional set theory.
Instead of characterizing absolute relationships, the Living Algorithm computes the dynamic context of the current moment in a data stream. In such a way, it characterizes the ongoing process of the data stream. Further, the context of process is far more important than content in determining results. As such, the Living Algorithm's mathematical processes describe contextual, rather than absolute, relationships.
Closed versus Open Functions
Functions can be either open or closed. Both traditional functions and recursive functions can be closed. The Mandelbrot equations from fractal mathematics provide examples of recursive functions that are closed.
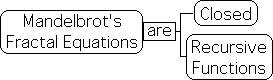
No new data enters into the systems described by closed functions. While closed functions frequently attempt to describe data flows, data streams are not part of the function. In contrast, the data stream is part of the function for the Living Algorithm. As it is open in this way, new data enters into the system with each iteration, i.e. repetition of the mathematical process. As such, the result is a function of the previous result as well as the data stream, signified by DN.
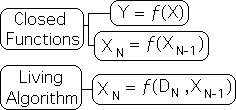
This difference has significant ramifications. For closed equations, the outcome is automatic once the initial conditions are set. For the Living Algorithm, the initial conditions fade in importance with each repetition of the mathematical process. As such, the initial conditions are relatively insignificant. While the starting point is relatively unimportant, the current data point tends to be the more significant in terms of current results for the Living Algorithm.
The following table summarizes these differences.
Traditional Functions |
Living Algorithm |
|---|---|
Well-founded & Regular (Obedient) |
Self-referential (Disobedient) |
Obeys Laws of Traditional Set Theory |
Doesn't Obey Set Theory |
Continuous |
Iterative & Discretized |
Characterizes Absolute Relationships |
Characterizes Contextual Processes |
Closed to New Data |
Open to New Data |
Initial Conditions Most Important |
Current Data Most Important |
From even a casual glance at the table, it is obvious that the properties and purpose of the Living Algorithm are entirely different than the traditional functions employed by physicists and chemists.
Living Algorithm's Data Streams vs. Probability's Data Sets
Traditional Probability specializes in data sets. The Living Algorithm specializes in data streams. Data sets and data streams are both composed of numbers. We differentiate the two in order to distinguish between the mathematical intent and measures of the Living Algorithm and those of Probability.
Data streams are ongoing; data sets are static. The Living Algorithm's measures are individual. Probability's measures are general. The LA's measures change with the addition of each new data point. As no new data points are added, Probability's measures are permanent. The LA characterizes the dynamic context of a stream of numbers; Probability characterizes the fixed features of a set of numbers.
Let's look at some specifics. The traditional equations of Probability operate upon data sets to yield probabilistic measures. These include averages of many varieties, for instance the mean and standard deviation.
![]()
These measures define the essences of the entire data set. For instance, the set of adult women might have an average height of 5' 6" with a standard deviation of 2".
![]()
Probability also has mathematical techniques that compare data sets. They generate the correlation between two data sets and the significance of this correlation.
How does the Living Algorithm differ? In contrast to Probability's traditional focus upon static data sets, the LA only operates upon data streams. Its computational process yields the derivatives of the data stream.
![]()
Instead of applying to the entire data set, they only apply to the current position in the data stream. With each iteration of the LA's process, the current data point is blended mathematically with the most recent derivatives to generate a current set of derivatives. These derivatives supply the dynamic context for the current moment in the data stream. In this sense, the Living Algorithm generates the mathematics of the moment.
![]()
The Living Algorithm's data stream derivatives also serve as probabilistic measures. These include averages and deviations. However these measures only apply to the data stream's current moment, not the entire data set. For example, the current average of a Sleep data stream could be 6.7 hours per night with a current deviation of 0.2 hours.
In characterizing the current moment, these measures also predict the location of the next data point in the stream. In our example, the individual with those stats is most likely to sleep between 6.5 to 6.9 hours the next evening. Further it is unlikely that this person will sleep over 7.1 hours or under 6.3 hours.
Further these same measures can be employed to generate correlations between 2 data streams. However again, these correlations only apply to the current moment, not the entire data set. For example, let us suppose that there is a high positive correlation between 2 data streams. If the next data point in one stream rose, it would be highly likely that the next data point in the other stream would also rise.
Because these predictive measures only apply to moments, not the entire data set, and because the data stream is live and open, hence less predictable, they provide rough approximations rather than precise predictions. These descriptive predictors could be likened to weather prediction. Although they are not mathematically precise, they are much better than nothing.
Probability's measures are also approximations. However, the mathematical parameters of the predictions are tightly defined. This is because data sets are closed.
In summary, the functions of traditional Probability identify the general features of the entire data set, not the individual moments of a data stream. While Probability's measures are general, the Living Algorithm's data stream derivatives are individual. The mathematics only applies to the moment.
| Probability | Living Algorithm |
|---|---|
Operates upon Closed Data Sets |
Operates upon Open Data Streams |
Measures apply to entire Data Set |
Measures apply to Individual Moments |
Identifies General Features of Data Set |
Identifies Dynamic Context of Data Stream |
Precise Predictions |
Rough Approximations |
Electronic Information Processing vs. Living Algorithm's Information Digestion
While Probability specializes in fixed data sets, our electronic devices frequently process live data streams. 'Streaming' is a modern word that indicates this relationship. As mentioned, the Living Algorithm's sole specialty is data streams. However the computational process and intent of electronics and the LA are entirely different. We employ the terms 'information processing' and 'information digestion' to indicate this difference in computational style and intention.
While data processing is a general term that applies to any type mathematical procedure that transforms information from one form to another, we broke it into 2 categories to facilitate communication. Under this limited definition, information processing aims at exact replication of the data stream's content, while information digestion provides the ongoing, dynamic context to the data stream. What are the implications of this differentiation?
Traditional information theory was developed in part to ensure the exact replication of information. The mathematical theory has enabled us to receive coherent messages from distant spacecraft as well as the precise transmission of radio, TV and Internet signals from the source to our homes. Exact replication is very important to our modern world.
In order to achieve this miraculous technological feat, information was deliberately stripped of meaning and transformed into binary form - 1s and 0s. In such a fashion, our CDs, DVDs and computers are able to store music, photos, text, and movies in abstract digital form. These digital storage devices don't contain any meaning. The information is composed of independent 1s and 0s that don't interact with each other in any way. For clarity of communication, this type of numerical transformation is referred to as 'information processing'.
Rather than the more traditional word 'process', we employ the word 'digest' to indicate the Living Algorithm's computational process. It seemed appropriate as there are many parallels between food digestion with the LA's data digestion process. One provides nourishment for the Body; the other for the Mind.
However, the primary intent is to differentiate the LA's computations from the standard electronic processing that aims at exact replication, whether text, music or video. In contrast the LA's digestion process generates composite figures that indicate dynamic context of the data stream. Although incorporated into these composite measures, the raw data is lost.
In order to provide dynamic context to the moments of the data stream, the numbers 'interact'. In other words, the current data stream derivatives are based upon a blending of the impact of the current data point with the prior derivatives. Below is a graph that indicates this 'interaction' between data points. (Note that this interaction between data points is entirely unacceptable when exact replication is the goal.)
The graph is a visualization of the ongoing acceleration of a data stream composed entirely of 1s. The y-axis indicates the acceleration, while the x-axis indicates the number of iterations of the LA's mathematical process. The acceleration of each 'moment' is a summation of the current acceleration with the graded accumulation of the accelerations of previous 'moments'. In other words, each of the previous moments exerts an impact upon the current moment. In such a fashion, the numbers interact.
Let us summarize. Electronic processing, as defined, aims at exact replication of the data stream, i.e. preserving the absolute essence of information, whether text, music or movies. This is achieved by isolating the numerical information in an absolute digital form. In the process of preserving essence, meaningful context is lost.
In contrast, information digestion via the Living Algorithm provides the dynamic context of each moment in a data stream. To convey dynamic context, the numerical information interacts. Due to this interaction, the numerical essence is lost.
Absolute Essence vs. Contextual Process
An overall pattern seems to be emerging. Traditional functions identify absolute relationships between variables, i.e. the permanent essence of the relationship. Probability defines the permanent essence of static data sets. Information processing, as defined, preserves the permanent essence of dynamic data streams. In other words, these traditional mathematical systems specialize in permanent essence.
It is no wonder that the scientific community is obsessed with the permanent essences associated with these mathematical systems. Understanding the absolute relationships between variables allows them to make miraculously precise predictions regarding the behavior of matter. Understanding the permanent essence of data sets allows scientists to define precise parameters for establishing the correlations between dissimilar groups. And preserving the absolute essence of data streams enables the precise accuracy of our 21st century Internet transmissions that a vast majority of us depend upon. In brief, inventors, engineers and scientists were able to generate our marvelous technological world due to the almost divine dependability of the permanent essences defined by traditional mathematical systems.
Instead of identifying permanent essence, the Living Algorithm's mathematical process identifies a data stream's constantly changing dynamic context.
Traditional Functions |
Identifies Permanent Essence of Relationships |
Probability |
Identifies Permanent Essence of Fixed Data Sets |
Electronic Processing |
Preserves Permanent Essence of Dynamic Data Streams |
Living Algorithm |
Identifies Dynamic Context of Data Streams |
The LA's probabilistic measures only provide rough approximations for the immediate future because of the constant potential for change. Due to this lack of permanent essence, is the Living Algorithm just a mathematical curiosity?
'Boring' Number Strings
Although the Living Algorithm is only able to generate immediate approximations rather than long range predictions, a multitude of distinctive mathematical processes emerge when this special algorithm digests a data stream composed of identical elements, deemed a Number String. On the most basic level, the data stream acceleration describes a Pulse. There are a multitude of other mathematical processes associated with the digestion of Number Strings.
This feature of the Living Algorithm's mathematical system separates it from the others. Traditional mathematical systems tend to ignore Number Strings altogether - not even a name. They have good reason. Number Strings are boring when viewed from traditional mathematical perspectives. Let's see why.
If a Number String, i.e. identical elements, were graphed like a traditional function, it would consist of a simple horizontal line of points, not even a continuous line. This discontinuous set of points would have no derivatives. If approximated with an imaginary line, the velocity would be a constant, and all the higher derivatives would equal zero. For Probability, the average would be one of the identical elements and the standard deviation would equal zero. If a Number String were employed to make a CD, there would be but a single sound. For these traditional mathematical approaches, a Number String is not worth considering, as its essence is elementary, i.e. a constant.
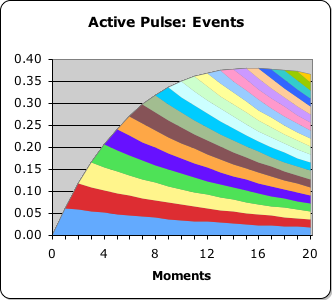
After a certain duration, the Number String is equally boring in the Living Algorithm system as the data stream derivatives/measures zero out. However, when the Living Algorithm digests a non-zero Number String, the initial results are fascinating. Six levels of Directionals (directed acceleration) are pictured in the graph below.
The first Pulse of Directional derivatives is based upon a Number String of 1s; the middle Pulse upon a Number String of 0s; and the final Pulse upon another Number String of 1s. If any of these Number Strings had been extended, all the derivatives would have continued to approach 0, as is evident from the graph.
6 levels of Directed Acceleration

While the static essence of the Number String is boring, the dynamic processes associated with digesting these identical elements are fascinating. In terms of results, the dynamic context is more significant than the essence of the Number String. Is this just another mathematical curiosity, with no scientific utility?
Amazingly, there are multiple patterns of correspondence between these mathematical processes and human behavior. They indicate that human attention tends to become entrained to the mathematical processes of the LA that are associated with Number Strings1. Even more startling, certain biological systems associated with attention seem to have evolved to take advantage of these processes. In other words, both our cognitive and biological systems associated with attention appear to entrain to the mathematical processes associated with Number Strings.
In fact, it seems that these dynamic processes do a better job of characterizing human attention than do the permanent essences of traditional mathematical systems. Dynamic context seems to be more important that static content in determining the behavior of attention.
A question arises: why does human attention tend to become entrained to these mathematical processes? Is there some undiscovered permanent essence that will provide an explanation for this mystery? Or is it possible that humans digest information via the Living Algorithm?
This brief exposition illustrates that traditional mathematical systems specialize in essential content, while Living Algorithm specializes in dynamic context. Check out the article Attention's Mathematical Tool to see why the Living Algorithm is more suited to be Atention's point-of-contact information digestion system than are the more traditional mathematical approaches.
Footnote
1 Some of the mathematical processes that emerge when the Living Algorithm digests Number Strings are summarized in the section Number Strings: Mathematical Overview.